 This is an archive version of the document. To get the most up-to-date information, see the current version.
This is an archive version of the document. To get the most up-to-date information, see the current version.Indexes
To reduce the amount of cost-expensive operations incurred by your cloud storage provider, as well as to decrease redundant traffic being sent over the network while offloading your data to object storage repositories, Veeam Backup & Replication uses indexes.
Indexes behavior is as follows:
- Indexes are created (or updated) during each offload session and consist of hash values of blocks that are being transferred to the object storage repository. These hashes are retrieved from meta information of your backup files (.vbk, .vib, or .vrb).
- Indexes are stored in the ArchiveIndex directory that is located on the source extent from which the backup data was offloaded.
On each subsequent offload session, Veeam will reuse these indexes to verify whether new blocks that are about to be transferred to the object storage repository have not been offloaded earlier. Verification is done by comparing existing indexes hashes with that of a block being transferred.
- Indexes are built per backup chain and cannot have any cross references to any other backup chains.
- Indexes are updated every time a backup chain is modified. For example, some data might have been removed due to the retention policy threshold, or you may have removed it manually. Both scenarios will modify your indexes upon the next successful offload session to maintain consistency.
- Corrupted indexes can be rebuilt anew by using the Rescan feature, as described in Rescanning Scale-Out Repositories.
Once rebuilt, Veeam will have to wait for 24 hours before it can offload any data again. This is done to comply with the Eventual Consistency model of Amazon S3.
ArchiveIndex Directory Structure
When Veeam creates indexes, it also creates and maintains the following directory structure on each extent from which the data is being offloaded.
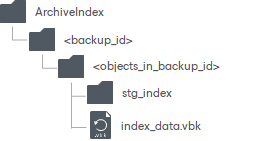
Directory | Description |
ArchiveIndex | The root directory for keeping indexes. This directory is created in the repository of an extent. |
<backup_id> | Contains objects in a backup file. |
<objects_in_backup_id> | An identifier of an object in a backup file.
|
stg_index | Contains actual indexes of the offloaded backup files (.vbk, .vib, or .vrb). |
index_data.vbk | Contains meta information on hash values stored in index files. |
Related Topics