 This is an archive version of the document. To get the most up-to-date information, see the current version.
This is an archive version of the document. To get the most up-to-date information, see the current version.Failover and Failback for Replication
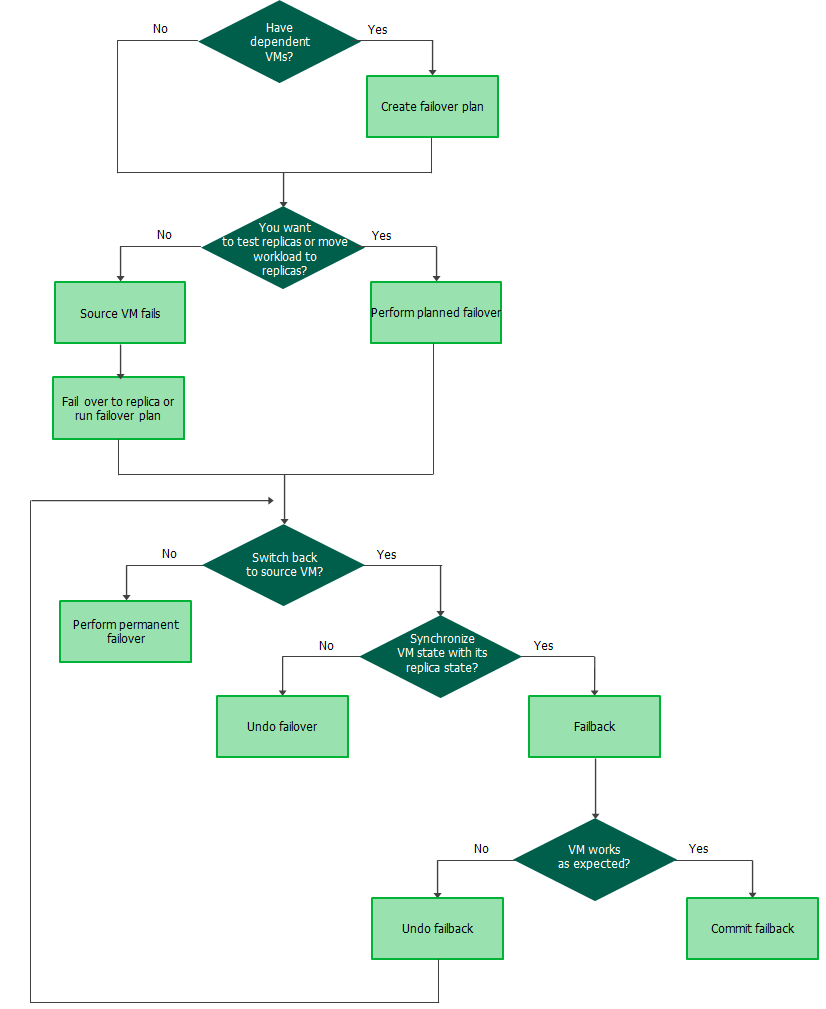
Failover and failback operations help you ensure that your business will function even if a disaster strikes your production site. Failover is a process of switching from the original VM on the source host to its VM replica on a host in the disaster recovery site. Failback is a process of returning from the VM replica to the original VM.
Veeam Backup & Replication provides the following failover and failback operations:
- Perform failover
When you perform failover, you shift all processes from the original VM in the production site to the VM replica in the disaster recovery site. Failover is an intermediate step that needs to be finalized: you can undo failover, perform permanent failover or perform failback.
For more information on how failover is performed, see Failover.
- Perform planned failover
When you perform planned failover, you shift all processes from the original VM to its replica. Planned failover is helpful when you know that the original VM is about to go offline, for example, you plan to perform datacenter maintenance, and you want to proactively switch the workload to the replica. The procedure is designed to transfer the current workload, that is why it does not suggest to select a restore point.
For more information on how planned failover is performed, see Planned Failover.
- Create failover plan
When you create a failover plan, you define the order in which Veeam Backup & Replication must perform failover for VMs, and an interval of time for which Veeam Backup & Replication must wait before starting the failover operation for the next VM in the list.
For more information on failover plans, see Failover Plan.
- Perform permanent failover
When you perform permanent failover, you permanently switch from the original VM to a VM replica and use this replica as the original VM. You can use this scenario if the original VM and VM replica are located in the same site and are nearly equal in terms of resources. Otherwise, perform failback.
For more information on how permanent failover is performed, see Permanent Failover.
- Undo failover
When you undo failover, you switch back to the original VM and discard all changes made to the VM replica while it was running. You can use the undo failover scenario if you have failed over to the VM replica for testing and troubleshooting purposes, and you do not need to synchronize the original VM state with the current state of the replica.
For more information on how failover undo is performed, see Failover Undo.
- Perform failback
When you perform failback, you switch back to the original VM and send to the original VM all changes that took place while the VM replica was running. If the source host is not available, you can recover a VM with the same configuration as the original VM and switch to it. For more information on how failback is performed, see Failback.
When you perform failback, changes are only sent to the original/recovered VM but not published. You must test whether the original/recovered VM works with these changes. Depending on the test results, you can do the following:
- Commit failback. When you commit failback, you confirm that the original/recovered VM works as expected and you want to get back to it.
For more information on how failback commit is performed, see Failback Commit.
- Undo failback. When you undo failback, you confirm that the original/recovered VM is not working as expected and you want to get back to the VM replica.
For more information on how failback undo is performed, see Failback Undo.
Veeam Backup & Replication supports failover and failback operations for one VM and for several VMs. In case one or several hosts fail, you can use batch processing to restore operations with minimum downtime.
The following scheme can help you decide at which moment which operations are preferable.
In This Section