Unstable Behavior from OpsMgr Health Service
Symptoms
You observe unstable behavior from the OpsMgr agent, such as:
- Heartbeat failure or other availability alerts
- Agent restarts
- Gaps in collected VMware data in reports or charts
- Agent and VMware objects appear ‘grayed out’ in the OpsMgr console.
You may receive alerts in OpsMgr that the Health Service (agent) on the Veeam Collector server is not heartbeating, as shown below:
Alert name: Health Service Heartbeat Failure Alert description: The Health Service on computer [server name] failed to heartbeat. |
Additional errors and warnings in the Operations Manager event log on the Collector server may appear, including those shown below:
Veeam Collector Health Service version store error Source: Health Service ESE StoreEvent ID: 623 Level: Error Description: HealthService (1080) Health Service Store: The version store for this instance (0) has reached its maximum size of [nn]Mb. It is likely that a long-running transaction is preventing cleanup of the version store and causing it to build up in size. Updates will be rejected until the long-running transaction has been completely committed or rolled back. KB for this rule should note that ‘maximum size nn MB’ should match what is set by Veeam (auto) HS configuration task. Also note this alert may arrive late, depending on whether HealthService was able to deliver the event for processing. ----------------------------------- Veeam Collector Health Service agent restart error Event Type: Warning Event Source: Health Service Script Event ID: 6024 Description: LaunchRestartHealthService.js : Launching Restart Health Service. Health Service exceeded Process\Handle Count or Private Bytes threshold. KB for this rule should note that this restart action should be disabled by nworks_overrides MP – check that override MP was imported. ----------------------------------- Veeam Collector: Health Service delay in event processing NOTE: This rule should check for Veeam in the log Name. Source: Health Service Modules Event ID: 26017 Level: Warning Description: The Windows Event Log Provider monitoring the [Veeam log name] is [n] minutes behind in processing events. This can occur when the provider is restarted after being offline for some time, or there are too many events to be handled by the workflow. ----------------------------------- Veeam Collector: Health Service cannot load configuration Source: HealthService Event ID: 1230 Level: Error Description: New configuration cannot be loaded, the error is 0x80FF0004(0x80FF0004). Management group "[MG name]". ----------------------------------- Veeam Collector: Health Service state change flow stalled Source: HealthService Event ID: 5300 OR 5302 OR 5304 Level: Error Description: Local health service is not healthy. Monitor state change flow is stalled with pending acknowledgment. ----------------------------------- Veeam Collector: Health Service send queue exceeded Source: HealthService Event ID: 2023 Level: Error The health service has removed some items from the send queue for management group "[MG name]" since it exceeded the maximum allowed size of [N] megabytes. |
Cause
The OpsMgr Health Service is overloaded when trying to process the incoming VMware data.
Either the required configuration has not been applied, or there are too many monitoring jobs (vSphere hosts) assigned to this Collector.
Some of the above events have specific solution steps. Review the solutions below for details.
Solution 1. Clear the Agent Health Service State
When the agent is exhibiting unstable behavior, heartbeat failures, or logging the above events, it is usually required to clear the Health Service State first. This is the local agent cache. Clearing this data will restore communications with the agent and allow further troubleshooting steps to be effective.
Note |
You should first remove monitoring jobs from the Collector — otherwise the OpsMgr agent may become overloaded during troubleshooting. Only when the agent is stable again should you re-apply monitoring jobs to the Collector. |
To clear the agent Health Service State:
- Stop the System Center Management service on the Collector server.
- Delete the Health Service State folder, typically:
- For a Management Server, %Program Files%\Microsoft System Center 2016\Operations Manager\Server\Health Service State.
- For an OpsMgr agent, %Program Files%\Microsoft Monitoring Agent\Agent\Health Service State.
- Start the System Center Management service.
- Observe the Operations Manager event log on the server. You should see configuration being loaded, management packs being deployed, and so on. When the agent is running in stable fashion, continue with troubleshooting.
Solution 2. Health Service version store error
Some events indicate that the required configuration has not been applied. In particular Event 623 as shown below will include the size of the Version Store (the agent local processing cache). If the size shown in this event is less than [nn]MB, then the Configure Health Service task has not been run against this Collector server.
Source: Health Service ESE Store Event ID: 623 Level: Error Description: HealthService (1080) Health Service Store: The version store for this instance (0) has reached its maximum size of [nn]Mb. It is likely that a long-running transaction is preventing cleanup of the version store and causing it to build up in size. Updates will be rejected until the long-running transaction has been completely committed or rolled back. |
Solution: Run the Configure Health Service task as follows:
In the Monitoring view, open the Veeam for VMware > Veeam Collectors > _Veeam Collectors node.
After discovery of Collector applications is complete in OpsMgr, you will see the _Veeam Collectors view populated with the Collectors.
Note |
If the view is empty, you should wait for discovery to complete. |
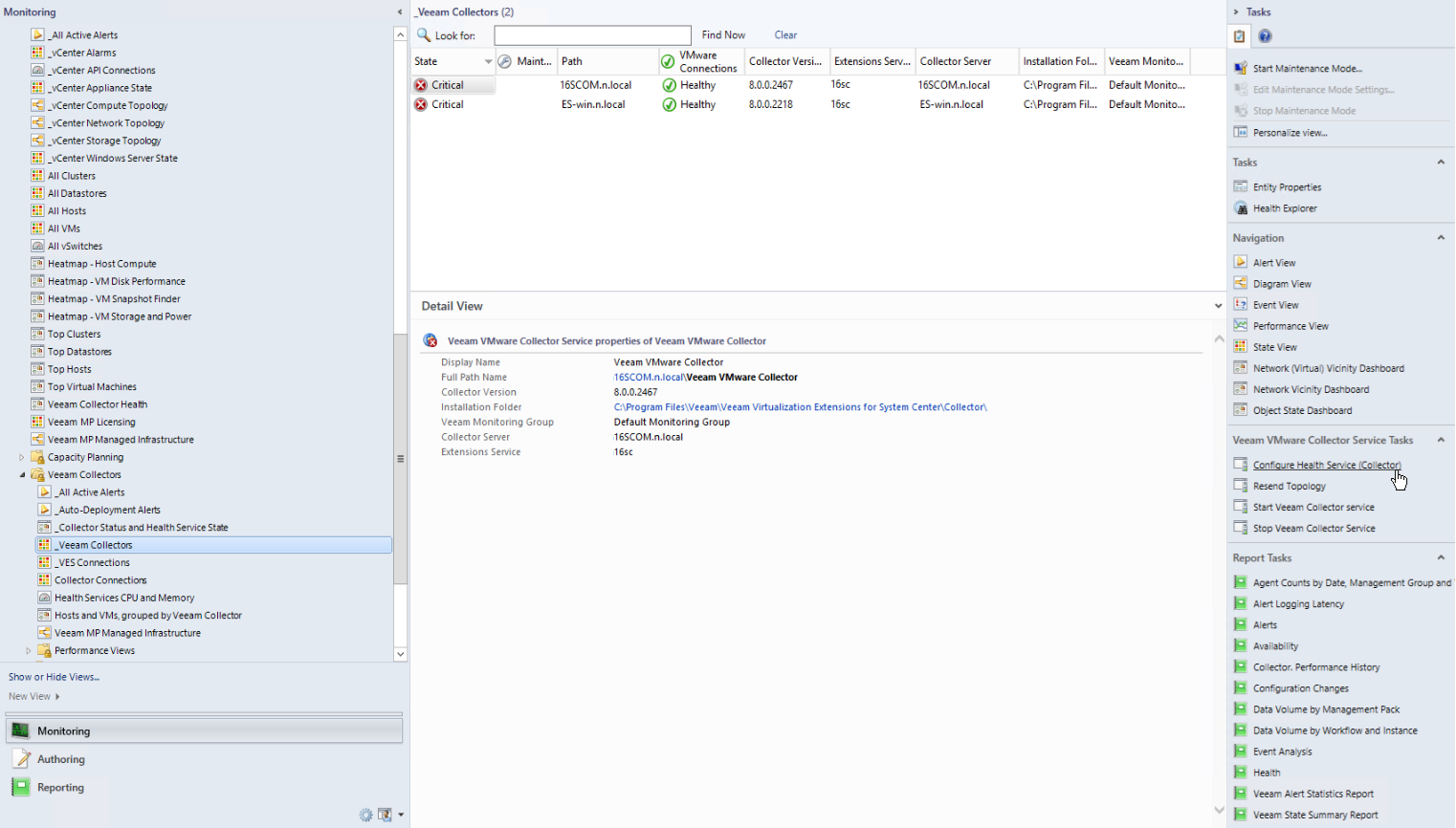
Then do the following:
- In the Actions pane, expand Veeam VMware Collector Service Tasks and click the Configure Health Service task (outlined in red above).
- Run this task against the Collector. Tasks may be run simultaneously. The task will cause the System Center Management service to restart.
Successful task output should look like the one below:
Output Setting Persistence Version Store Maximum...done Setting Persistence Cache Maximum...done Setting State Queue Items...done Enumerating Management Groups...done Setting MaximumQueueSizeKb for [Mgt Group name]...done Error None Exit Code: 0 |
Solution 3. Health Service agent restart error
The OpsMgr agent will auto-restart if certain thresholds are breached. This is a default behavior in OpsMgr which must be modified with overrides when an agent is acting as a Veeam Collector.
Event 6024 shows that the out-of-box monitors for Private Bytes or Handle Count have fired and are restarting the agent:
Source: Health Service Script Event ID: 6024 Level: Warning Description: LaunchRestartHealthService.js : Launching Restart Health Service. Health Service exceeded Process\Handle Count or Private Bytes threshold. Note that the Required Health Service Overrides MP which is part of the standard Veeam MP for VMware set will disable this Health Service restart action when the Veeam Collector is installed. Check that the overrides MP has been imported. |
Solution: Use the pre-built ‘Overrides MP’ as supplied in the Veeam MP for VMware installation ISO to apply the required thresholds. For details, see the Installation Guide.
Solution 4. Miscellaneous Agent Errors and Continued Instability
If errors and unstable behavior continue even after the correct configuration is applied as above, then the following solutions should be considered:
- Relocate the Veeam Collector roles to OpsMgr Management Servers. A Management Server will scale higher in terms of monitored vSphere hosts and VMs per Collector. Note that in large environments you may need to dedicate Management Servers to the role of VMware data processing.
- Relocate monitoring jobs (vSphere clusters/hosts) to other Veeam Collectors to distribute the monitoring load.