Backup Infrastructure for Unstructured Data Backup
To protect your unstructured data, you can use your existing Veeam Backup & Replication infrastructure. To do so, configure the following components:
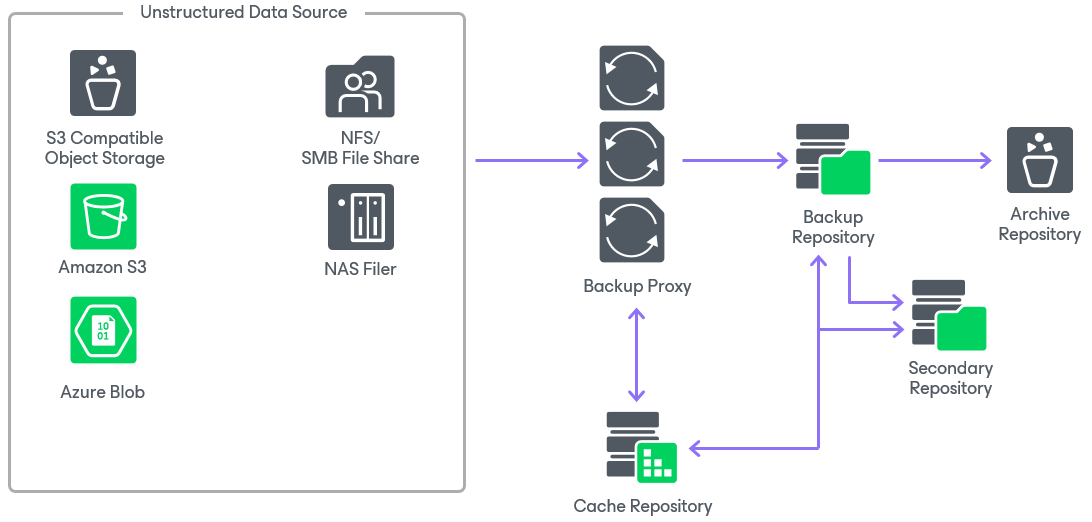
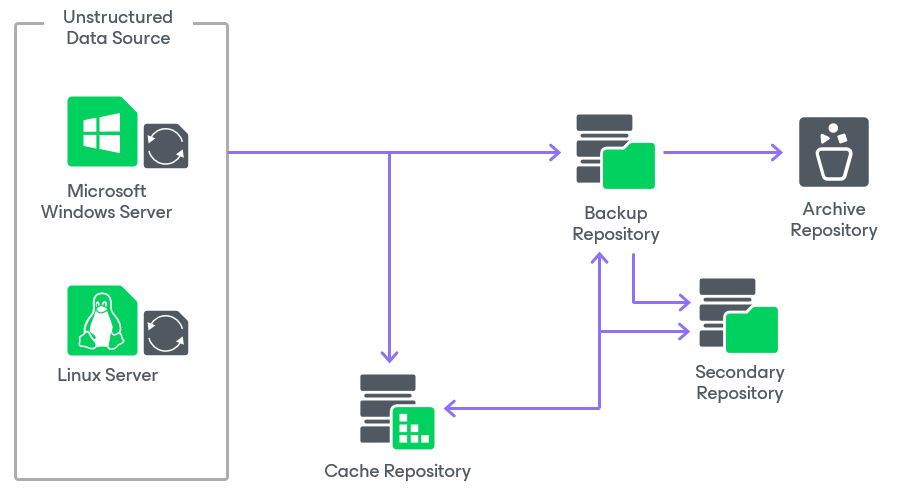
For system requirements for unstructured data backup components, see the System Requirements section.
|
Note |
|
Backup of the content of file shares and object storage repositories is not supported by Veeam Cloud Connect. |
To learn how backup components interact during the unstructured data backup, see the How Unstructured Data Backup Works section.
Unstructured data supported as a source for backup by Veeam Backup & Replication includes:
A file share is a storage device or data source available to multiple hosts through a computer network.
For supported file shares, requirements and limitations, see Workloads.
File backup jobs in Veeam Backup & Replication can read data from the following sources:
- SMB (CIFS) path
- NFS path
- Path to the storage snapshot folder
- VSS snapshot
|
Note |
|
Consider the following limitations:
|
To learn how to add file shares to the inventory of the virtual infrastructure, see the Adding Unstructured Data Source section.
An object storage is storage based on either a cloud solution or an S3 compatible on-premises storage solution.
For supported object storage, requirements and limitations, see Workloads.
To learn how to add object storage as a source for backup to the inventory of the virtual infrastructure, see the Adding Object Storage section.
General-Purpose Backup Proxies
A general-purpose backup proxy is an architecture component that sits between the unstructured data source and other components of the backup infrastructure. In case of Microsoft Windows and Linux servers, the role of the general-purpose backup proxy is assigned to these servers instead of a dedicated one. The backup proxy operates as a data mover that transfers data between the data source and the backup repository. The backup proxy processes jobs and delivers backup and restore traffic.
For more information on general-purpose backup proxies, their requirements, limitations and deployment, see the General-Purpose Backup Proxies section.
After you configure the backup proxy, choose it to process the backup traffic from unstructured data sources, as described in the Adding NFS File Share, Adding SMB File Share, Adding S3 Compatible Object Storage, Adding Amazon S3 Object Storage, and Adding Microsoft Azure Blob Storage sections.
A cache repository is a storage location where Veeam Backup & Replication keeps temporary metadata and uses it to reduce the load on the data source during the backup procedure. The cache repository keeps track of all objects that have changed between each backup session. This allows performing incremental backups from the unstructured data source fast and efficiently. If you store your unstructured data backups on an object storage repository, the cache repository also stores active metadata. For more information, see the Data Structure in Backup, Archive and Secondary Repositories and Unstructured Data Backups in Object Storage Repositories sections.
You can assign the role of a cache repository to a backup repository added to the Veeam Backup & Replication infrastructure. To assign this role, select the backup repository as a cache repository when adding an unstructured data source.
|
Note |
|
You can not assign the role of a cache repository to deduplicating storage appliances. |
To minimize the network load during backup, locate the cache repository closer to the backup proxy in the computer network: at the best, they should be located on one machine.
A backup repository is a main storage location where Veeam Backup & Replication keeps all versions of backed up files for the configured period and metadata files. Backups stored in the backup repository can be used to quickly restore the entire file share to the state as of a specific restore point.
[Optional] If you want to retain specific files for a longer period of time, you can use cheaper devices for archive purposes. To enable file archiving, configure Veeam Backup & Replication to move backup files and metadata files from the backup repository to an archive repository. By default, usage of the archive repository is disabled and, after the retention period for the backup repository is over, backup files are deleted.
[Optional] If you want to store a copy of the unstructured data backup in a different repository, you can configure a secondary repository where Veeam Backup & Replication will copy all backups created in the backup repository. The secondary repository can have its own retention policy and encryption settings. By default, no secondary repository is configured.
The following table describes which roles can be assigned to different storage types.
|
Storage Type |
Backup Repository |
Archive Repository |
Secondary Repository |
|---|---|---|---|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✕ |
✓ |
|
|
✓ |
✓ |
✓ |
|
|
✓ |
✕ |
✓ |
|
|
✕ |
✕ |
✕ |
1 If you use a Dell PowerScale (formerly Isilon) storage system in the CIFS Share Access mode, make sure that you have assigned your service account to the built-in BackupAdmin role within PowerScale. Otherwise, the access to the share will be denied.
2 If you plan to use HPE StoreOnce storage appliances, consider the following recommendations for optimal performance:
- For HPE StoreOnce Gen3 or Gen4 software versions earlier than 4.3.x, large backup loads (exceeding 1PB) should be spread across multiple Catalyst stores on the same StoreOnce system. For HPE StoreOnce Gen4 software version 4.3.x and Gen5, this 1PB limit does not apply.
- Do not include Catalyst stores in a SOBR intended for unstructured data backups. This will reduce the global deduplication of the StoreOnce system.
3 An object storage repository added as a capacity tier in a scale-out backup repository cannot be used for storing unstructured data backups. To archive unstructured data backup files to an object storage repository, assign the object storage repository as an archive repository when you create a file backup job.
4 SOBR consisting of object storage repositories cannot be used as a target backup repository for file backup jobs.
5 Consider the following limitations:
- Amazon S3 Glacier and Azure Blob Storage Archive Tier are not supported for unstructured data backup.
- Amazon S3 Snowball Edge and Azure Databox are not supported as archive repositories for unstructured data backup, but you can use them as backup repositories, secondary repositories, or targets for copying file share backups.
- You cannot use S3 compatible repositories with multiple buckets as a target repository for Unstructured Data. This includes backup, archive, or secondary repositories.
You can create two object storage repositories pointing to the same cloud folder/bucket and use these repositories for storing both unstructured data backups and Capacity Tier backups at the same time: one object storage repository will be used to store unstructured data backups, the other one – to store virtual and physical machine backups as a capacity tier in a single SOBR. However, these object storage repositories (mapped to the same cloud folder) must not be used across multiple Veeam Backup & Replication servers for the same purposes as it leads to unpredictable system behavior and inevitable data loss.
Deployment of Backup, Archive and Secondary Repositories
To use a storage, which is already added to the Veeam Backup & Replication Backup Infrastructure, to store unstructured data backups, define it as a target storage when creating a file backup job or an object storage backup job:
- Configure the backup repository at the Backup Repository step of the wizard when creating file backup jobs and object storage backup jobs.
- Configure the backup repository at the Archive Repository step of the wizard when creating file backup jobs and object storage backup jobs.
- Configure the backup repository at the Secondary Target step of the wizard when creating file backup jobs and object storage backup jobs.
If the required storage is not added as a backup repository in your Veeam Backup & Replication Backup Infrastructure, add it as described in the Backup Repositories section.
In This Section